Types of File Organization
1. Heap File (Unordered)
Records are stored in the order they are inserted - no particular ordering.
Unordered File Organization Details
- Records are typically added at the end of the file, without following any specific order.
- This insertion method allows only linear search, resulting in slower search times.
- Despite slow searches, maintenance including insertion and deletion is simpler.
- No reorganization of the entire file is needed, making maintenance easier.
- If file is unordered, number of block accesses required to reach correct block which contains the desired record is O(n), where n is the number of blocks.
Unordered File Organization Example
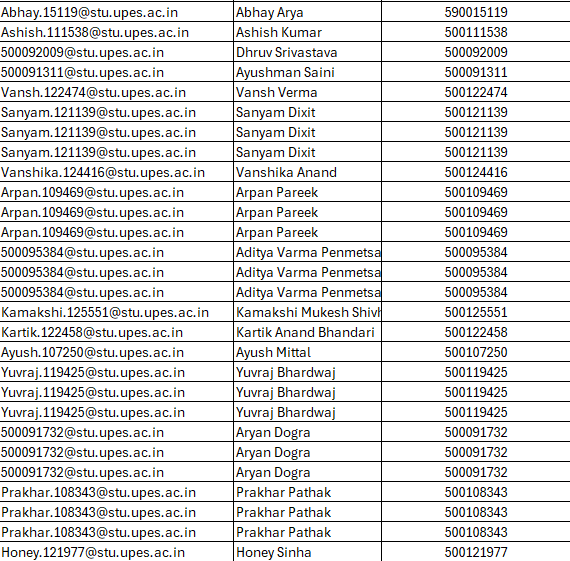
✓ Advantages: Fast insertion (O(1)), simple structure, no reorganization needed
✗ Disadvantages: Slow search (O(n) - linear scan), inefficient for queries
2. Sequential File (Ordered)
Records are stored in order based on a key field.
Ordered File Organization Details
- All the records in the file are ordered on some search key field.
- Here binary search is possible. (Similar to searching for a page in a book - you can jump to the middle, then decide whether to go forward or backward, significantly reducing search time)
- Maintenance (insertion & deletion) is costly, as it requires reorganization of entire file.
- Important Note: We will get binary search only if we are using that key for searching on which indexing is done, otherwise it will behave as unsorted file.
- If file is ordered, number of block accesses required to reach correct block which contains the desired record is O(log2n), where n is the number of blocks.
Ordered File Organization Example
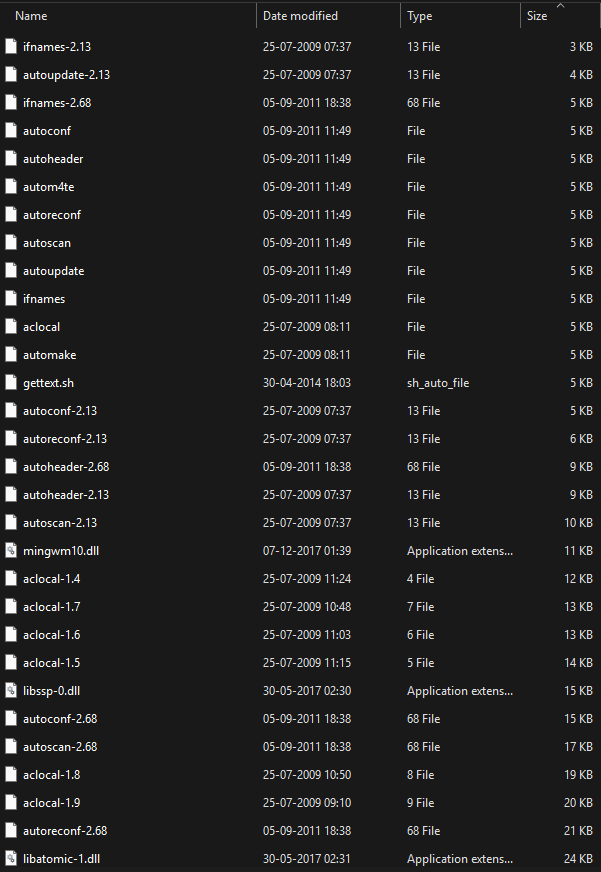
✓ Advantages: Efficient for range queries, binary search possible (O(log2n))
✗ Disadvantages: Expensive insertions/deletions, requires reorganization
3. Hash File
Records are distributed across buckets using a hash function.
✓ Advantages: Fast exact-match queries
✗ Disadvantages: Poor for range queries, collisions
Why Do We Need Indexing?
Foundation: Relational Databases and Set Theory
- Relational databases are based on set theory.
- In set theory, the order of elements is unimportant, similarly in database tables.
- However, in practical implementation, element order in tables is often specified.
- Various operations such as search, insertion, and deletion are influenced by the order of elements in the tables.
- Elements in a table can be stored in two ways: sorted (ordered) or unsorted (unordered).
Problem: Searching through millions of records sequentially is extremely slow!
Consider a database with 1 million records:
- Without Index: Average 500,000 record accesses
- With Index: Approximately 20 record accesses (using B+ tree)
Real-World Analogy
An index in a database is like an index in a book:
- Book index: Find page numbers quickly without reading entire book
- Database index: Find records quickly without scanning entire file
Example: Book Index

Just like a book's index helps you find topics quickly, a database index helps locate records efficiently.